import sys
from pathlib import Path
sys.path.insert(1, str(Path.cwd().parent)) 28 Document Loading
Source: https://learn.deeplearning.ai/courses/langchain-chat-with-your-data
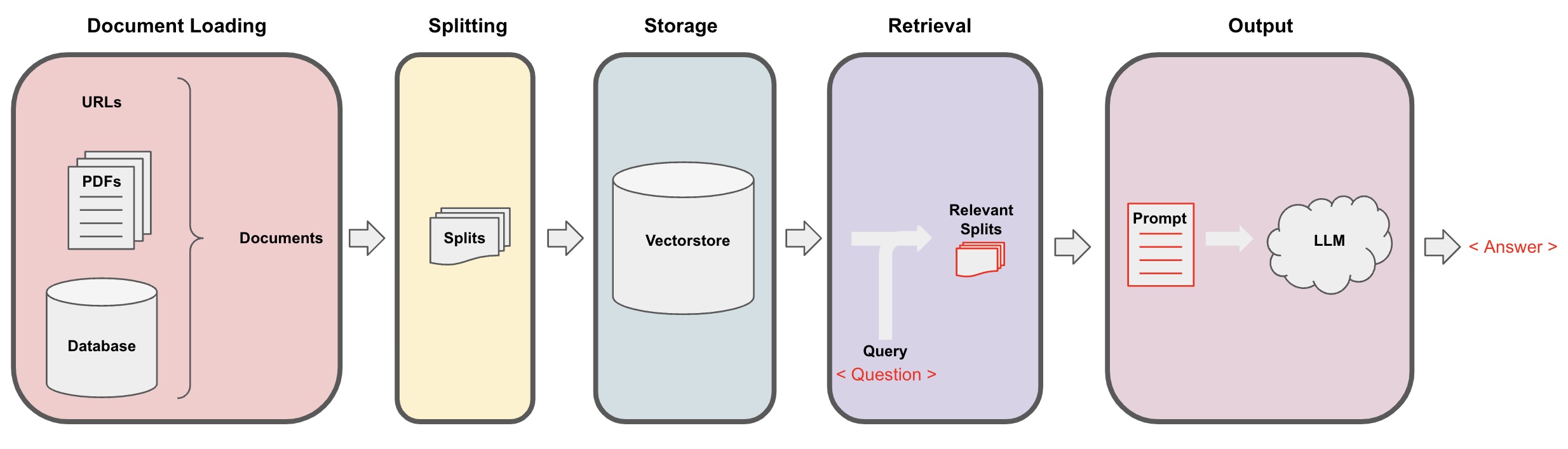
28.1 Retrieval augmented generation
In retrieval augmented generation (RAG), an LLM retrieves contextual documents from an external dataset as part of its execution.
This is useful if we want to ask question about specific documents (e.g., our PDFs, a set of videos, etc).
import os
import openai
import sys
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']28.2 PDFs
Let’s load a PDF transcript from Andrew Ng’s famous CS229 course! These documents are the result of automated transcription so words and sentences are sometimes split unexpectedly.
# The course will show the pip installs you would need to install packages on your own machine.
# These packages are already installed on this platform and should not be run again.
#! pip install pypdf from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/MachineLearning-Lecture01.pdf")
pages = loader.load()Each page is a Document.
A Document contains text (page_content) and metadata.
len(pages)22page = pages[0]print(page.page_content[0:500])MachineLearning-Lecture01
Instructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine
learning class. So what I wanna do today is just spend a little time going over the logistics
of the class, and then we'll start to talk a bit about machine learning.
By way of introduction, my name's Andrew Ng and I'll be instructor for this class. And so
I personally work in machine learning, and I've worked on it for about 15 years now, and
I actually think that machine learning is the page.metadata{'producer': 'Acrobat Distiller 8.1.0 (Windows)',
'creator': 'PScript5.dll Version 5.2.2',
'creationdate': '2008-07-11T11:25:23-07:00',
'author': '',
'moddate': '2008-07-11T11:25:23-07:00',
'title': '',
'source': 'docs/MachineLearning-Lecture01.pdf',
'total_pages': 22,
'page': 0,
'page_label': '1'}28.3 YouTube
from langchain.document_loaders.generic import GenericLoader
from langchain_community.document_loaders.blob_loaders import FileSystemBlobLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader# ! pip install yt_dlp
# ! pip install pydubNote: This can take several minutes to complete. This has been modified relative to the lesson video to fetch the video file locally.
url="https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir="docs/youtube/"
loader = GenericLoader(
YoutubeAudioLoader([url],save_dir), # fetch from youtube
# FileSystemBlobLoader(save_dir, glob="*.m4a"), #fetch locally
OpenAIWhisperParser()
)docs_yt = loader.load()[youtube] Extracting URL: https://www.youtube.com/watch?v=jGwO_UgTS7I
[youtube] jGwO_UgTS7I: Downloading webpage
[youtube] jGwO_UgTS7I: Downloading tv client config
[youtube] jGwO_UgTS7I: Downloading player c548b3da
[youtube] jGwO_UgTS7I: Downloading tv player API JSON
[youtube] jGwO_UgTS7I: Downloading ios player API JSON
[youtube] jGwO_UgTS7I: Downloading m3u8 information
[info] jGwO_UgTS7I: Downloading 1 format(s): 140
[download] docs/youtube//Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a has already been downloaded
[download] 100% of 69.76MiB
[ExtractAudio] Not converting audio docs/youtube//Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a; file is already in target format m4a
Transcribing part 1!
Transcribing part 2!
Transcribing part 3!
Transcribing part 4!from src.fs import write_pickle
write_pickle(docs_yt, "pkl/docs_yt.pkl")docs_yt[0].page_content[0:500]"Welcome to CS229 Machine Learning. Uh, some of you know that this is a class that's taught at Stanford for a long time. And this is often the class that, um, I most look forward to teaching each year because this is where we've helped, I think, several generations of Stanford students become experts in machine learning, got- built many of their products and services and startups that I'm sure, many of you or probably all of you are using, uh, uh, today. Um, so what I want to do today was spend s"28.4 URLs
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://github.com/basecamp/handbook/blob/master/titles-for-programmers.md")USER_AGENT environment variable not set, consider setting it to identify your requests.Note: the URL sent to the WebBaseLoader differs from the one shonw in the video because for 2024 it was updated.
docs = loader.load()print(docs[0].page_content[:100])
handbook/titles-for-prog28.5 Notion
Follow steps here for an example Notion site such as this one:
- Duplicate the page into your own Notion space and export as
Markdown / CSV. - Unzip it and save it as a folder that contains the markdown file for the Notion page.

from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("docs/Notion_DB")
docs = loader.load()print(docs[0].page_content[0:200])docs[0].metadata